2021年,中國人工智能產業在政策引導、市場需求和技術突破的驅動下,迎來了關鍵的發展階段。其中,人工智能基礎軟件開發作為整個產業鏈的“根基”和“引擎”,呈現出加速創新、國產化替代、開源生態繁榮等顯著趨勢,深刻塑造著產業格局。
一、自主可控成為核心戰略,國產化替代加速推進
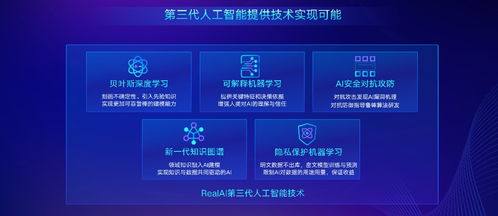
在2021年,面對全球技術競爭和供應鏈安全挑戰,發展自主可控的人工智能基礎軟件成為國家戰略共識。國內企業和科研機構在深度學習框架、AI芯片配套軟件棧等核心領域加大投入。以百度飛槳(PaddlePaddle)、華為昇思MindSpore等為代表的國產深度學習框架,不僅在性能上持續優化,更通過降低開發門檻、適配國產硬件、構建本土化應用生態等方式,市場份額和開發者社區規模顯著增長。芯片廠商也積極打造從硬件驅動、算子庫到編譯器的全棧軟件能力,力求實現“軟硬一體”的自主化解決方案。
二、開源開放生態持續深化,社區協同效應凸顯
開源已成為人工智能基礎軟件開發的主流模式。2021年,中國在開源領域的參與度和貢獻度進一步提升。頭部企業不僅開源其核心框架,還將模型庫、開發工具和行業解決方案開源,吸引全球開發者共建。例如,飛槳的開源模型數量大幅增加,覆蓋了計算機視覺、自然語言處理、語音等多個領域。產學研各界通過開源社區緊密協作,加速了技術迭代和創意落地,降低了創新成本,推動了AI技術的普惠化。
三、與行業應用深度融合,開發平臺走向“工業化”
基礎軟件開發不再局限于技術本身,而是更加注重與垂直行業的深度融合。2021年,AI基礎軟件平臺呈現出“工業化”特征,即提供從數據準備、模型訓練、部署推理到管理監控的全流程、標準化、自動化工具鏈。這極大地提升了企業(尤其是傳統行業企業)應用AI的效率。面向醫療、金融、制造、城市管理等具體場景的專用開發套件和低代碼/無代碼平臺不斷涌現,使非AI專家也能快速構建和部署智能應用,加速了AI的產業滲透。
四、大模型推動開發范式變革,算力與數據挑戰并存
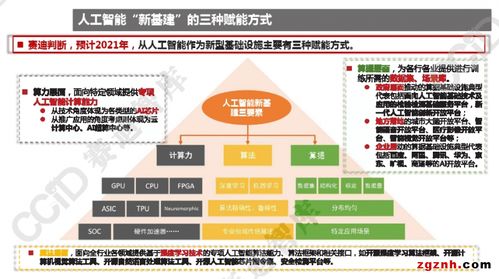
以超大規模預訓練模型為代表的“大模型”技術成為2021年的熱點,這為基礎軟件開發帶來了新范式。開發重點從“從頭訓練”更多轉向基于大模型的“精調”和“應用”。這對基礎軟件提出了新要求:需要支持千億甚至萬億參數模型的分布式訓練、高效的推理部署以及便捷的微調工具。大模型也放大了對算力基礎設施和海量高質量數據的需求,如何高效管理和調度算力、構建數據治理體系,成為基礎軟件開發中必須解決的配套挑戰。
五、標準化與安全性日益受到重視
隨著AI應用規模的擴大,其可靠性和安全性問題備受關注。2021年,中國在AI基礎軟件的標準化建設方面取得進展,圍繞模型格式、接口規范、評測基準等制定了一系列標準和規范,旨在促進不同框架和平臺間的互操作性。針對AI模型的安全(如對抗攻擊)、隱私保護(如聯邦學習支持)、可解釋性等,基礎軟件開始原生集成相關工具和功能,推動負責任AI的發展。
中國人工智能基礎軟件開發將繼續沿著自主創新、生態融合、普惠應用的道路前行。它不僅是技術競爭的焦點,更是推動千行百業智能化轉型、構筑數字經濟新優勢的關鍵基石。